-
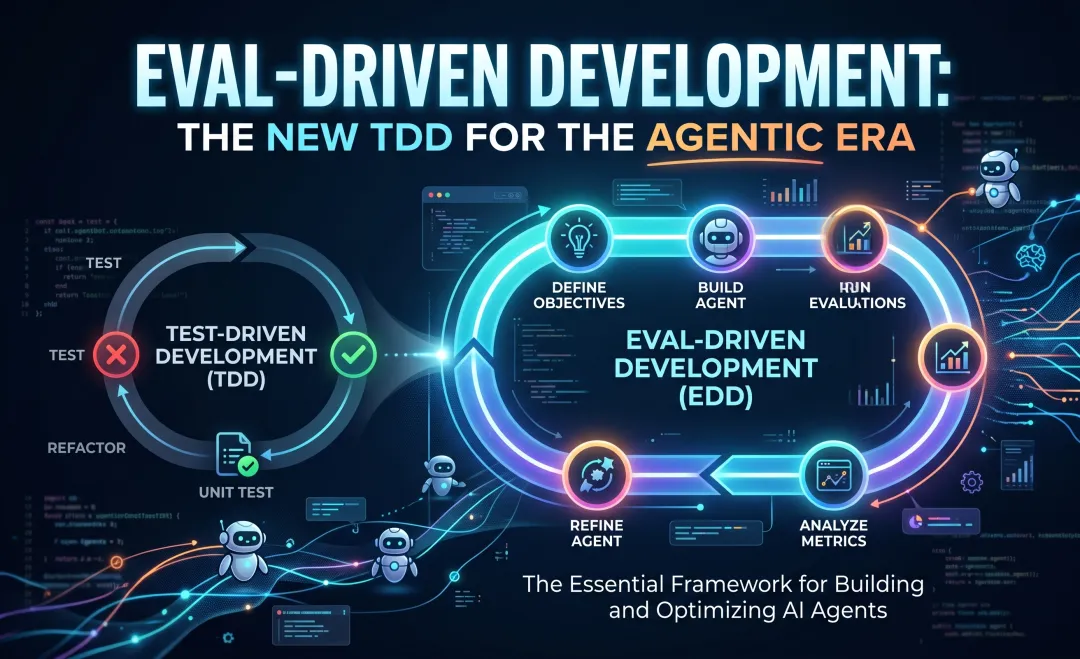
Eval-Driven Development: The New TDD for the Agentic Era
-

The Agentic Developer Interview: What to Ask and What to Expect
-
From Code to Strategy: Why AI is Forcing Developers to Become Domain Experts
-
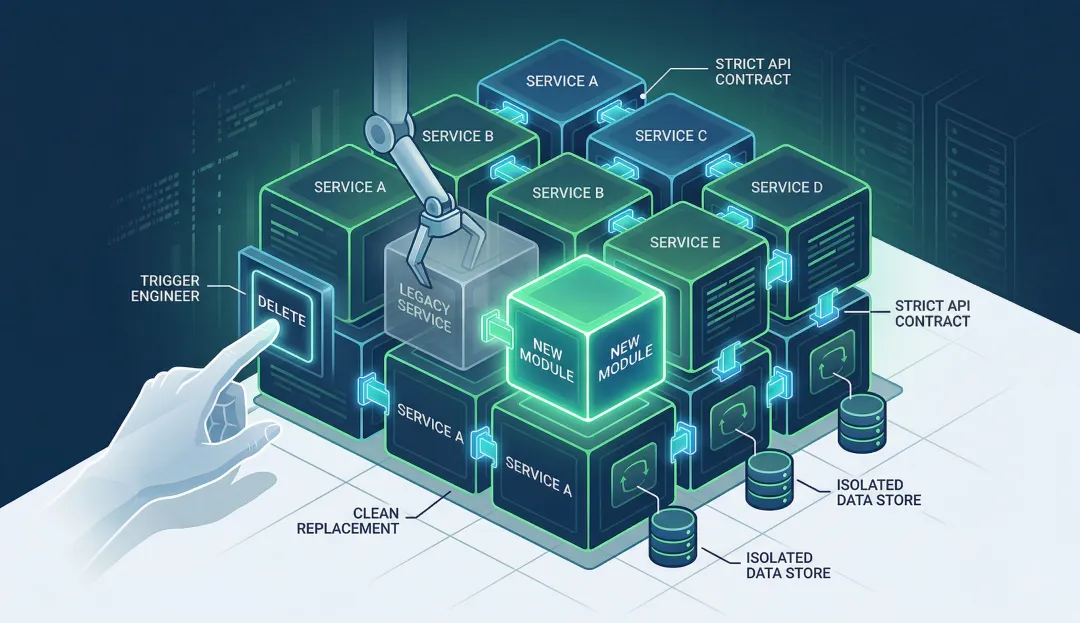
Engineering Your Own Exit: Why Deletion is the Ultimate Senior Flex
-

The Future of Software: Next-Gen Specification Driven Development in the Age of AI Agents
-

The Keeper Test in the AI Era: Building Teams That Cannot Be Automated
-
Architecting the Ultimate Digital Brain: Obsidian, AI CLI, and Gemini via MCP
-

Show Me Your Traffic, and I’ll Tell You Who You Are
-

Fix Slow Queries Now: Must-Know Indexing Hacks!
-

The Cost of Hurry: When Organizational Change Hits a Wall
-

AI in Your Pocket: How GPTs Are Transforming Our Everyday Lives
-

Beyond the Eye Rolls: The Undermining Impact of Passive Aggression in the Workplace
-

Code Crafter or Team Captain? Navigating Your Engineering Career Path
-

Astonishing Engineering: Balancing between Democracy and Communism
-

Unveiling the Top Books and Authors from Lenny Rachitsky’s Podcast
-

Unlocking the Business Benefits of CI/CD
-

Loose coupling or lose your mind
-

Software Engineering Team Topologies
-

The Imperative Role of Technical Excellence and Prudent Design in Enabling Agile Development at Scale
-

DORA: How to Measure the Healthiness of Your Apps
-

Every company is happy to pay technical debt.
-

Continuous Cleaning in Software Engineering: Making Code as Spotless as Your Grandma’s Kitchen!