Smart Models, Dumb Pipes: Why Your Agentic Workflow Needs 'Agentic Ops', Not Just Claude Opus
The software engineering landscape of 2026 is a study in stark contradictions. On one side of the ledger, enterprises are reporting an average ROI of 171% on agentic AI implementations, with some US-based firms pushing past the 190% mark. On the other side, a cold shadow is creeping across the industry: 40% of custom agentic projects are currently slated for cancellation before they ever see a production environment.
This bifurcated reality is rarely discussed in the hype-cycles of LinkedIn or the glossy slides of management consulting firms. The common narrative suggests that if your agent isn’t performing, you simply need a “smarter” model. If Claude 3.5 Sonnet failed, upgrade to Claude 4.6 Opus. If GPT-4o hallucinated, wait for the next reasoning-heavy iteration. This is the “Smart Model, Dumb Pipes” fallacy, and it is the primary reason for the staggering failure rate we are witnessing today.
The hard truth is that in 2026, raw model intelligence has become a commodity. The performance delta between the top-tier frontier models has narrowed to a negligible 3 to 7 percent across most reasoning benchmarks. Your competitive advantage is no longer the brain you rent from OpenAI or Anthropic. Your moat is the infrastructure you build to constrain, evaluate, and integrate that brain into your business. You don’t need a smarter model: you need Agentic Ops.
I. The “Smart Model, Dumb Pipes” Fallacy
Most failed agentic initiatives follow a predictable pattern. A team of engineers takes a frontier model with a massive context window and attempts to bolt it directly onto a legacy system. They treat the LLM as a magical “universal translator” that can navigate unstructured documentation, undocumented APIs, and inconsistent data schemas.
This approach fails because it assumes that intelligence can compensate for structural chaos. When you feed an agent a 15-year-old SOAP API with zero schema validation and ask it to “figure it out,” you aren’t being innovative: you are being negligent. Even the most advanced reasoning models like Claude Opus 4.7 will eventually succumb to “contextual noise” when forced to navigate dumb pipes.
The result is a catastrophic feedback loop. The agent encounters an ambiguous API response, “reasons” its way into an incorrect assumption, executes a destructive tool call, and then consumes thousands of output tokens trying to explain why the database is suddenly empty. In this scenario, a higher-intelligence model doesn’t fix the problem: it just creates a more articulate and expensive failure.
II. The Agentic Ops Architecture
To avoid the 40% trap, engineering leaders must shift their focus from model selection to systems engineering. The most successful teams in 2026 share a common architectural pattern that decouples the “brain” (the LLM) from the “nervous system” (the orchestration layer).
graph TD
User([User Request]) --> Router{Prompt Router}
Router -->|High Complexity| Opus[Frontier Model: Claude Opus]
Router -->|Routine Task| Sonnet[Efficiency Model: Claude Sonnet]
Opus --> MCP[Model Context Protocol Layer]
Sonnet --> MCP
MCP --> Eval[Continuous Eval Harness]
Eval -->|Success| Tools[Structured Tools / APIs]
Eval -->|Failure| Retry[Refinement Loop]
Tools --> Response([Final Output])
This architecture prioritizes three critical components: the Model Context Protocol (MCP), a Two-Tier Stack strategy, and a Continuous Evaluation Harness.
1. Standardization via MCP
The Model Context Protocol (MCP) has emerged as the industry standard for tool-use and data integration. By implementing MCP, you ensure that your agents interact with your internal systems through a standardized, typed, and documented interface. This reduces the cognitive load on the model, allowing it to focus its reasoning tokens on the task at hand rather than deciphering your infrastructure.
2. The Two-Tier Stack Strategy
Relying solely on frontier models for every interaction is a recipe for financial ruin. Leading teams utilize a tiered approach: an “Efficiency Model” (like Llama 4-Light or Claude Sonnet) handles 80% of routine processing, while a “Frontier Model” (like Claude Opus) is reserved for high-level routing, complex reasoning, and recovery from errors. This hybrid approach reduces blended costs by 35 to 50 percent without sacrificing the quality of the final output.
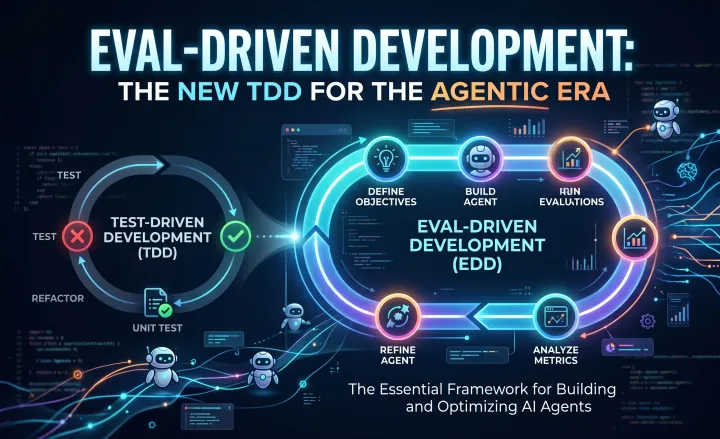
III. Evaluation Drift: The Silent Killer
The single biggest differentiator between a pilot that scales and a pilot that dies is the presence of an automated evaluation (Eval) harness. In traditional software engineering, we have deterministic tests. We know that if we input 2 + 2, the output must be 4. Agentic systems are stochastic. The same prompt can produce different outputs on different days.
Without a rigorous Eval harness, you are flying blind. “Vibe-based development”: the practice of manually checking a few agent responses and saying “looks good to me”: is the fast track to the 40% trap.
Best Practice: Mandate Eval-Driven Development (EDD). You must treat your Evals as first-class citizens in your CI/CD pipeline. Every change to a prompt, a tool definition, or a model version must be run against a representative dataset of historical interactions. If your “pass rate” drops by even 1%, the build should fail. We justify this rigor because stochastic systems cannot be tested deterministically: only statistical confidence can guarantee production stability.
IV. The CEO Blind Spot
The market mess of 2026 is exacerbated by a fundamental misunderstanding at the leadership level. Most CEOs see AI as a “plug-and-play” solution. They see the demos of agents coding entire applications or managing complex supply chains and assume the technology is ready for out-of-the-box deployment.
What they fail to see is the “Integration Tax.” They don’t see that for every $1 spent on model tokens, a successful enterprise spends $3 to $5 on clean data APIs, observability, and evaluation infrastructure. They see the intelligence, but they ignore the pipes.
As technical leaders, our job is to bridge this gap. We must explain that an agent is only as good as the context it is given and the constraints it is forced to respect. If you want the 171% ROI, you have to pay the Agentic Ops tax.
V. Conclusion: From Research to Systems Engineering
We have officially moved past the era of “AI Research.” The questions of whether an LLM can reason or whether it can code have been settled. We are now in the era of “Systems Engineering.”
The projects that fail in the coming year will not fail because the models weren’t smart enough. They will fail because the engineers were too lazy to build the harnesses, the architects were too distracted by the latest frontier releases to standardize their APIs, and the leadership was too blinded by the hype to invest in the boring, unsexy infrastructure of Agentic Ops.
Your CEO might be buying the smartest synthetic brain on the market, but if you bolt it to a rusted 15-year-old SOAP API and pray it figures it out, you’re not building an agent. You’re building a very expensive, highly articulate random number generator.
The future belongs to the orchestrators. Stop chasing the smartest model and start building the smartest pipes.